Code
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (8, 8)Now is the time to learn more about advanced architectures! As you build a network that predicts the next word in a sentence, you will learn more about recurrent neural networks and working with text as you build an autoencoder to reconstruct noisy images, visualize convolutional neural network activations, and use deep pre-trained models to classify images.
This Advanced Model Architectures is part of [Datacamp course: Introduction to Deep Learning with Keras] There is no denying that deep learning is here to stay! A powerful innovation tool, it is used to solve complex problems arising from unstructured data. It is among the frameworks that make it easier to develop deep learning models, and it is versatile enough to build industry-ready models quickly. In this course, you will learn regression and save the earth by predicting asteroid trajectory, apply binary classification to distinguish real and fake dollar bills, learn to apply multiclass classification to decide who threw which dart at a dart board, and use neural networks to reconstruct noisy images. Additionally, you will learn how to tune your models to enhance their performance during training.
This is my learning experience of data science through DataCamp. These repository contributions are part of my learning journey through my graduate program masters of applied data sciences (MADS) at University Of Michigan, DeepLearning.AI, Coursera & DataCamp. You can find my similar articles & more stories at my medium & LinkedIn profile. I am available at kaggle & github blogs & github repos. Thank you for your motivation, support & valuable feedback.
These include projects, coursework & notebook which I learned through my data science journey. They are created for reproducible & future reference purpose only. All source code, slides or screenshot are intellactual property of respective content authors. If you find these contents beneficial, kindly consider learning subscription from DeepLearning.AI Subscription, Coursera, DataCamp
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (8, 8)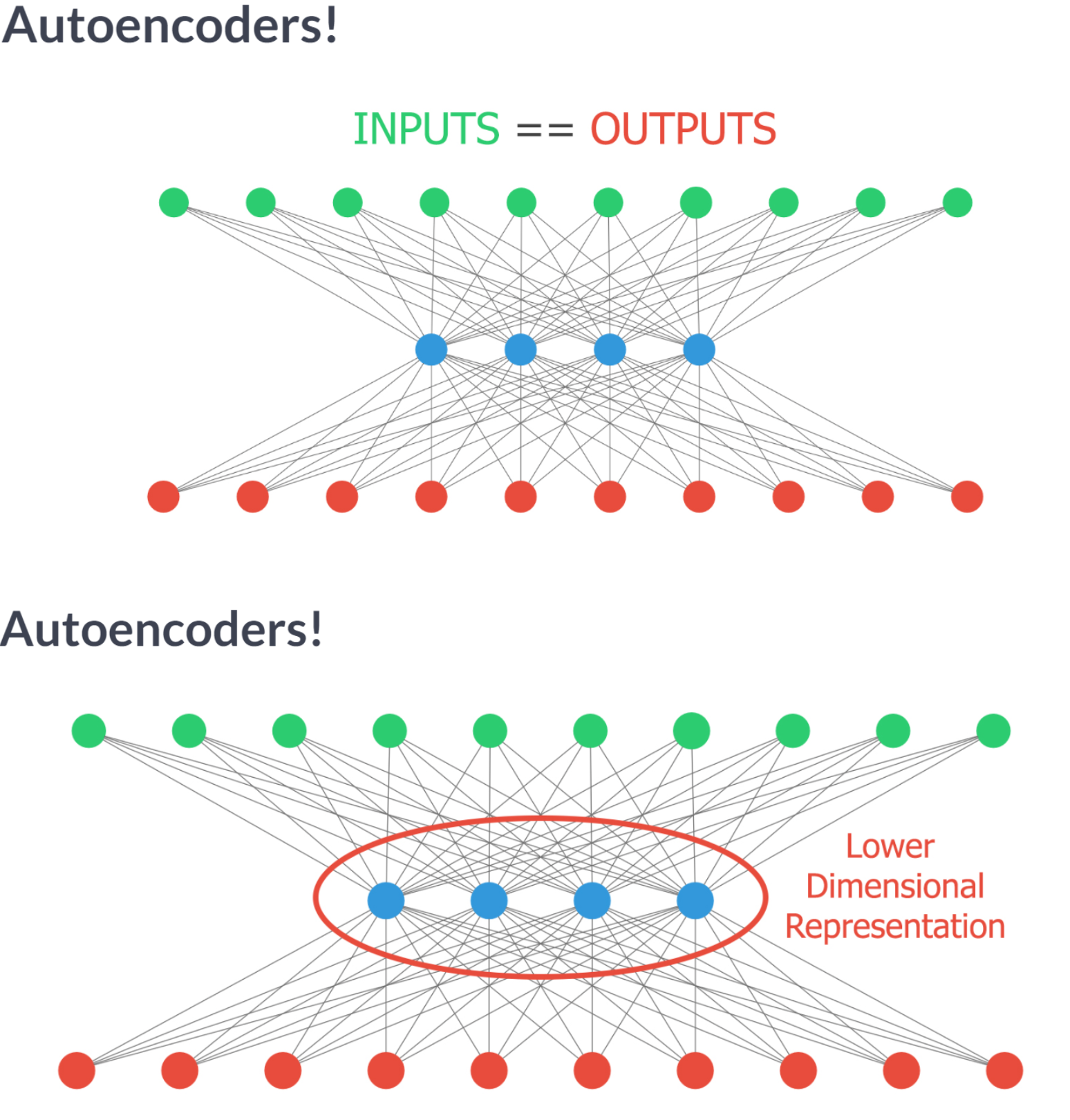
If you have already built a model, you can use the model.layers and the tf.keras.backend to build functions that, provided with a valid input tensor, return the corresponding output tensor.
This is a useful tool when we want to obtain the output of a network at an intermediate layer.
For instance, if you get the input and output from the first layer of a network, you can build an inp_to_out function that returns the result of carrying out forward propagation through only the first layer for a given input tensor.
banknote = pd.read_csv('dataset/banknotes.csv')
banknote.head()| variace | skewness | curtosis | entropy | class | |
|---|---|---|---|---|---|
| 0 | 3.62160 | 8.6661 | -2.8073 | -0.44699 | 0 |
| 1 | 4.54590 | 8.1674 | -2.4586 | -1.46210 | 0 |
| 2 | 3.86600 | -2.6383 | 1.9242 | 0.10645 | 0 |
| 3 | 3.45660 | 9.5228 | -4.0112 | -3.59440 | 0 |
| 4 | 0.32924 | -4.4552 | 4.5718 | -0.98880 | 0 |
from sklearn.model_selection import train_test_split
X = banknote.drop(['class'], axis=1)
# Normalize data
X = ((X - X.mean()) / X.std()).to_numpy()
y = banknote['class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(2, input_shape=(4, ), activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()Metal device set to: Apple M2 Pro
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 2) 10
dense_1 (Dense) (None, 1) 3
=================================================================
Total params: 13
Trainable params: 13
Non-trainable params: 0
_________________________________________________________________import tensorflow.keras.backend as K
# Input tensor from the 1st layer of the model
inp = model.layers[0].input
# Output tensor from the 1st layer of the model
out = model.layers[0].output
# Define a function from inputs to outputs
inp_to_out = K.function([inp], [out])
# Print the results of passing X_test through the 1st layer
print(inp_to_out([X_test]))[array([[0. , 0.37549245],
[0. , 0. ],
[0. , 1.1705389 ],
[0.80350095, 0. ],
[0. , 0.45659196],
[0. , 0.39465803],
[0. , 0.2937718 ],
[1.6936306 , 0. ],
[0. , 1.7320554 ],
[1.6993406 , 0.24986142],
[0. , 0.0130935 ],
[0. , 0. ],
[1.242307 , 0. ],
[2.1809785 , 0. ],
[0. , 0. ],
[0.10098183, 1.4647627 ],
[1.3819088 , 0. ],
[0. , 1.5719738 ],
[0. , 0.3431489 ],
[0. , 0. ],
[1.4292371 , 0. ],
[0. , 0. ],
[0. , 0.47683764],
[0. , 1.0398089 ],
[0.69826394, 0. ],
[1.8231996 , 0.1518383 ],
[0.19345874, 0. ],
[2.0786335 , 0. ],
[1.7724708 , 0. ],
[0. , 0.37743545],
[0. , 0.9601868 ],
[1.5003294 , 0. ],
[2.1864011 , 0. ],
[1.3651726 , 0.50950533],
[0.9512666 , 0. ],
[0. , 1.0006309 ],
[0. , 1.0246115 ],
[0. , 0.7420771 ],
[1.4149433 , 0. ],
[0. , 0. ],
[0. , 0. ],
[1.3642219 , 0.46315208],
[0.6822637 , 0.44779772],
[1.2197626 , 0. ],
[0. , 0.8023678 ],
[3.0379872 , 0. ],
[1.0023434 , 0.5733885 ],
[0. , 0. ],
[0. , 1.9805212 ],
[0. , 0. ],
[0. , 0.8462728 ],
[0. , 0. ],
[0.41133392, 0.396342 ],
[1.8531082 , 0. ],
[0. , 1.3839779 ],
[0. , 0. ],
[2.197113 , 0. ],
[1.0838579 , 0. ],
[0.5885806 , 0. ],
[0. , 1.5197667 ],
[0. , 0. ],
[0. , 1.5575926 ],
[3.0960293 , 0. ],
[1.7432804 , 0. ],
[0. , 1.8278891 ],
[0. , 0.24996898],
[0. , 0. ],
[3.0219853 , 0. ],
[1.1064217 , 0.8184391 ],
[3.1221542 , 0. ],
[0. , 0.03845035],
[0. , 0.45214215],
[0.44748574, 0.9297856 ],
[0. , 0.68025804],
[0.41268438, 0.3487688 ],
[0.04583725, 0. ],
[1.5883161 , 0.01920176],
[0. , 1.9603978 ],
[1.815204 , 0.01541543],
[0. , 0.55857277],
[1.0656844 , 0.58844024],
[0.06546828, 1.1626966 ],
[0. , 0. ],
[1.0784036 , 0. ],
[0.86395097, 0.26222232],
[0. , 1.4465377 ],
[0.29322046, 0.42026457],
[0.77806246, 0.5933256 ],
[2.8007777 , 0. ],
[0. , 1.3130655 ],
[0. , 0.3838975 ],
[0. , 0.77335227],
[0. , 0.43116805],
[0. , 0.8187542 ],
[0. , 0.5691173 ],
[0. , 0. ],
[0. , 0. ],
[0. , 1.2105324 ],
[0. , 0.6683744 ],
[2.6871805 , 0. ],
[0. , 1.576623 ],
[0. , 1.7979519 ],
[1.4149102 , 0. ],
[0. , 1.7295202 ],
[1.8238373 , 0. ],
[0. , 0. ],
[0.67428875, 0. ],
[1.7480347 , 0. ],
[2.145006 , 0. ],
[0. , 0. ],
[0.32031894, 0.2607703 ],
[0. , 0. ],
[0. , 0.6326635 ],
[0. , 0. ],
[1.3515104 , 0.17855638],
[0. , 0. ],
[1.7645774 , 0. ],
[0.42124277, 0. ],
[0. , 0. ],
[1.7474351 , 0. ],
[0. , 0. ],
[0. , 1.4870965 ],
[0. , 0.3388745 ],
[0. , 0.96994126],
[0. , 0.6266229 ],
[0.5805801 , 0.54575163],
[0. , 0. ],
[0. , 0.4109331 ],
[0. , 0. ],
[0. , 0.5057498 ],
[1.9864713 , 0. ],
[0.48652747, 0. ],
[1.7786927 , 0. ],
[3.7561402 , 0. ],
[0.30513093, 1.0392137 ],
[0. , 0. ],
[0. , 0. ],
[0. , 0.25900382],
[1.4487793 , 0. ],
[0. , 0. ],
[0. , 0. ],
[0. , 1.077708 ],
[0. , 0. ],
[3.4231462 , 0. ],
[1.7313973 , 0. ],
[0. , 0.5502673 ],
[0. , 0. ],
[0. , 1.2172674 ],
[0. , 0.03463185],
[0. , 1.9237142 ],
[0.64094967, 1.0707436 ],
[0. , 0.04918486],
[0. , 0. ],
[0.39635363, 0.79355884],
[2.0931787 , 0. ],
[0. , 1.6677037 ],
[0. , 0.77816635],
[0. , 1.0718096 ],
[1.1238068 , 0. ],
[0. , 0. ],
[0. , 0.3486092 ],
[1.1254191 , 0. ],
[0. , 0.6752286 ],
[0. , 0. ],
[0. , 0.06280209],
[1.1808344 , 0. ],
[1.3216628 , 0. ],
[1.7229823 , 0. ],
[2.0050302 , 0. ],
[0. , 0.90579164],
[0. , 0.07136095],
[1.1891456 , 0. ],
[0. , 0.5639721 ],
[0. , 1.8011869 ],
[1.9583603 , 0. ],
[2.039433 , 0. ],
[1.7335049 , 0.1367445 ],
[0.15039636, 0.5245586 ],
[1.6244404 , 0. ],
[0. , 0.24477994],
[1.8833904 , 0. ],
[0. , 0. ],
[2.1456828 , 0. ],
[0.06797472, 1.1545227 ],
[0. , 0.6102477 ],
[0. , 0.97216463],
[2.3681862 , 0. ],
[0. , 0.5635488 ],
[0. , 1.7373589 ],
[0.22155677, 0. ],
[0. , 1.6336868 ],
[3.065762 , 0. ],
[1.5924762 , 0. ],
[1.0035732 , 0. ],
[0. , 0. ],
[0. , 1.85818 ],
[0. , 0. ],
[0. , 0.34124735],
[0.69382626, 0.315381 ],
[1.1751639 , 0. ],
[1.7070895 , 0. ],
[0. , 0.5228194 ],
[1.4166987 , 0. ],
[0.11257983, 0. ],
[1.5593911 , 0. ],
[0. , 0. ],
[2.2255094 , 0. ],
[0.7979871 , 0. ],
[0. , 0.18750837],
[0.41734374, 0. ],
[3.1221542 , 0. ],
[0. , 1.6958407 ],
[0.0459449 , 0. ],
[0.35276502, 0.55390406],
[0. , 0. ],
[0. , 0. ],
[2.105369 , 0. ],
[1.6274002 , 0. ],
[0. , 0. ],
[1.9817121 , 0. ],
[0. , 0.39465803],
[2.0020473 , 0. ],
[0.9793646 , 0. ],
[0. , 0. ],
[0. , 0.59752274],
[0. , 0. ],
[1.2058305 , 0. ],
[0. , 0.88647825],
[0. , 0.91598856],
[1.358753 , 0.27229068],
[0. , 0.1669504 ],
[0. , 1.3026557 ],
[0. , 1.8060746 ],
[0. , 0.24329005],
[0. , 1.610624 ],
[0.9264726 , 0.7765587 ],
[0. , 0.89599144],
[0. , 1.2729251 ],
[3.688808 , 0. ],
[0.48192278, 0.822033 ],
[0.9809349 , 0.67755866],
[0. , 0.7946866 ],
[1.4353545 , 0. ],
[0.34804404, 0.24274996],
[3.2713344 , 0. ],
[2.7760239 , 0. ],
[0. , 0. ],
[0. , 0. ],
[1.5827352 , 0.27386668],
[0.4189049 , 0.48474896],
[1.7800095 , 0. ],
[0. , 1.5644 ],
[0.03132896, 0.34841686],
[0. , 0.54557 ],
[0. , 1.5803874 ],
[0.34840798, 1.0118514 ],
[0. , 0. ],
[0.32658067, 0.54882336],
[1.7252634 , 0. ],
[0.09108783, 0.02495453],
[1.5466074 , 0. ],
[0.7881525 , 0. ],
[0. , 0.6773982 ],
[1.3724287 , 0. ],
[0. , 0.5134398 ],
[0.1160419 , 0.4974357 ],
[1.2189462 , 0. ],
[0. , 0. ],
[1.1679615 , 0.57351726],
[0. , 0.15649372],
[0.3726089 , 0.9017478 ],
[0. , 0.6686817 ],
[0.5684481 , 0.02686873],
[1.8689233 , 0. ],
[0. , 1.1575441 ],
[0. , 1.6906269 ],
[0. , 0.816877 ],
[1.8398101 , 0. ],
[0. , 0.48919895],
[1.516718 , 0. ],
[1.777486 , 0. ],
[2.2003236 , 0. ],
[0.76204586, 0. ],
[1.538575 , 0. ],
[0. , 2.028227 ],
[0. , 0.75489354],
[1.269642 , 0. ],
[1.5364683 , 0.40972048],
[0. , 0.49915534],
[0.26579776, 0. ],
[0. , 0. ],
[0.09593216, 1.4901001 ],
[0.42137474, 0.5429996 ],
[1.7456713 , 0. ],
[0.45864594, 1.1253911 ],
[1.2692437 , 0. ],
[0. , 0. ],
[1.7700084 , 0. ],
[0. , 0.06035864],
[1.6737996 , 0. ],
[0. , 0. ],
[2.1129045 , 0. ],
[1.9910865 , 0. ],
[0.6714376 , 0. ],
[0.3954507 , 0.63959926],
[0. , 0.9654005 ],
[0.8447262 , 0. ],
[0. , 1.3931822 ],
[0.7133221 , 0.6368634 ],
[0.5731597 , 0.06631845],
[0.41781852, 0.30369937],
[2.1999269 , 0. ],
[1.8163741 , 0. ],
[0. , 0. ],
[0. , 0.08380598],
[1.4117547 , 0.4217252 ],
[0. , 1.6243527 ],
[3.065762 , 0. ],
[2.0629985 , 0. ],
[0. , 0.34125647],
[2.3749108 , 0. ],
[0. , 1.3590873 ],
[1.4549739 , 0. ],
[0. , 0.11551914],
[0. , 1.0082576 ],
[0.46179688, 0.4511228 ],
[1.6254805 , 0. ],
[2.1958346 , 0. ],
[0. , 0. ],
[0.98309064, 0. ],
[0.9360188 , 0.40081674],
[0. , 1.4476349 ],
[0.7580173 , 0.7194294 ],
[0. , 0. ],
[2.5446153 , 0. ],
[0. , 0.11104237],
[2.1926975 , 0. ],
[0.74133575, 0. ],
[0. , 0.67770857],
[1.5960879 , 0.50949365],
[0.28525358, 0.0856876 ],
[0. , 0.8938494 ],
[0. , 1.7360221 ],
[1.4473945 , 0. ],
[0.8033388 , 0.6682485 ],
[0.9077512 , 0.66146827],
[0.4199238 , 0.23709951],
[1.5749146 , 0.18939644],
[1.6605623 , 0. ],
[0.14609009, 0. ],
[0. , 0. ],
[0.72675824, 0.79868126],
[0. , 0.49259654],
[0.06683069, 0.33397 ],
[0. , 0.8815694 ],
[0. , 0. ],
[0. , 0.6011565 ],
[0. , 0. ],
[0.655474 , 0.32405606],
[2.8831096 , 0. ],
[0.32197267, 0. ],
[0.7891792 , 0. ],
[0. , 0. ],
[1.2404824 , 0.57880586],
[0. , 1.6082227 ],
[0. , 0.48475215],
[1.3595093 , 0. ],
[0. , 0. ],
[0.4740765 , 0.884644 ],
[0. , 1.9149888 ],
[0.17719437, 1.269549 ],
[2.4637482 , 0. ],
[0. , 1.9930475 ],
[0. , 0. ],
[0. , 1.4054403 ],
[0. , 0.03241685],
[0. , 1.0035914 ],
[1.1201029 , 0. ],
[0. , 1.023931 ],
[0.42296836, 0.67176056],
[2.0657082 , 0. ],
[0.21039039, 0.28634548],
[0. , 0.58284056],
[0. , 1.0934013 ],
[2.519268 , 0. ],
[0.66955346, 0. ],
[0. , 0.917456 ],
[1.5495468 , 0. ],
[1.2930192 , 0. ],
[1.9903916 , 0. ],
[0. , 0. ],
[0.0496307 , 0. ],
[0. , 0.49773932],
[1.258089 , 0.16016045],
[3.4000864 , 0. ],
[1.3097886 , 0. ],
[0.39841253, 1.1097382 ],
[0.6334289 , 0. ],
[2.740962 , 0. ],
[0.3577386 , 0.23633905],
[0. , 0. ],
[1.9621279 , 0. ],
[0.12779573, 1.0938519 ],
[1.6681826 , 0.15242702],
[0.14252542, 0. ],
[0. , 1.4179412 ],
[0. , 0.9199592 ],
[0. , 0.48779106],
[2.3392625 , 0. ],
[0. , 1.3699207 ],
[0. , 1.7364304 ],
[2.2403967 , 0. ]], dtype=float32)]Put on your gloves because you’re going to perform brain surgery!
Neurons learn by updating their weights to output values that help them better distinguish between the different output classes in your dataset. You will make use of the inp_to_out() function you just built to visualize the output of two neurons in the first layer of the Banknote Authentication model as it learns.
def plot():
fig, axes = plt.subplots(1, 5, figsize=(16, 8))
for i, a in enumerate(axes):
a.scatter(layer_outputs[i][:, 0], layer_outputs[i][:, 1], c=y_test, edgecolors='none');
a.set_title('Test Accuracy: {:3.1f} %'.format(float(test_accuracies[i]) * 100.));
plt.tight_layout()model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy'])layer_outputs = []
test_accuracies = []
for i in range(0, 21):
# Train model for 1 epoch
h = model.fit(X_train, y_train, batch_size=16, epochs=1, verbose=0)
if i % 4 == 0:
# Get the output of the first layer
layer_outputs.append(inp_to_out([X_test])[0])
#layer_output = inp_to_out([X_test])[0]
# Evaluate model accuracy for this epoch
test_accuracies.append(model.evaluate(X_test, y_test)[1])2023-04-07 19:41:35.562033: W tensorflow/tsl/platform/profile_utils/cpu_utils.cc:128] Failed to get CPU frequency: 0 Hz13/13 [==============================] - 0s 6ms/step - loss: 0.6392 - accuracy: 0.6383
13/13 [==============================] - 0s 4ms/step - loss: 0.6001 - accuracy: 0.6845
13/13 [==============================] - 0s 4ms/step - loss: 0.5550 - accuracy: 0.7451
13/13 [==============================] - 0s 4ms/step - loss: 0.5094 - accuracy: 0.7985
13/13 [==============================] - 0s 4ms/step - loss: 0.4662 - accuracy: 0.8180
13/13 [==============================] - 0s 4ms/step - loss: 0.4256 - accuracy: 0.8447plot()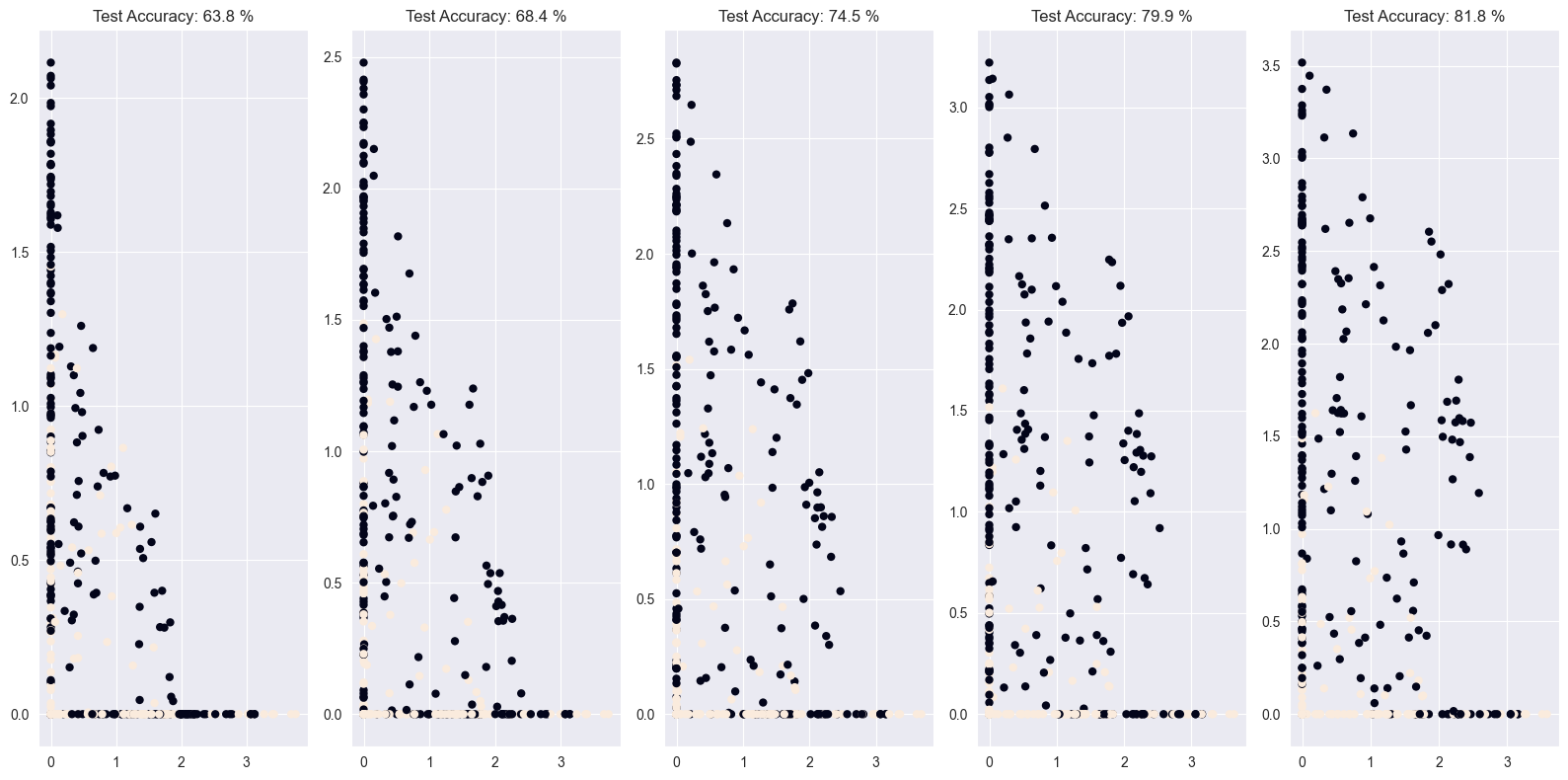
print("\nThat took a while! If you take a look at the graphs you can see how the neurons are learning to spread out the classes during training. Click in between graphs fast, it’s like a movie!")
That took a while! If you take a look at the graphs you can see how the neurons are learning to spread out the classes during training. Click in between graphs fast, it’s like a movie!Autoencoders have several interesting applications like anomaly detection or image denoising. They aim at producing an output identical to its inputs. The input will be compressed into a lower dimensional space, encoded. The model then learns to decode it back to its original form.
You will encode and decode the MNIST dataset of handwritten digits, the hidden layer will encode a 32-dimensional representation of the image, which originally consists of 784 pixels (28 x 28). The autoencoder will essentially learn to turn the 784 pixels original image into a compressed 32 pixels image and learn how to use that encoded representation to bring back the original 784 pixels image.
from tensorflow.keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.astype('float32') / 255.
X_test = X_test.astype('float32') / 255.
X_train = X_train.reshape((len(X_train), np.prod(X_train.shape[1:])))
X_test = X_test.reshape((len(X_test), np.prod(X_test.shape[1:])))
X_test_noise = np.load('dataset/X_test_MNIST_noise.npy')
X_test_noise = X_test_noise.reshape((len(X_test_noise), np.prod(X_test.shape[1:])))
y_test_noise = np.load('dataset/y_test_MNIST.npy')autoencoder = Sequential(name='autoencoder')
# Add a dense layer with input the original image pixels and neurons the encoded representation
autoencoder.add(Dense(32, input_shape=(784, ), activation='relu'))
# Add an output layer with as many neurons as the original image pixels
autoencoder.add(Dense(784, activation='sigmoid'))
# Compile your model with adadelta
autoencoder.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Summarize your model structure
autoencoder.summary()Model: "autoencoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 32) 25120
dense_3 (Dense) (None, 784) 25872
=================================================================
Total params: 50,992
Trainable params: 50,992
Non-trainable params: 0
_________________________________________________________________Okay, you have just built an autoencoder model. Let’s see how it handles a more challenging task.
First, you will build a model that encodes images, and you will check how different digits are represented with show_encodings(). To build the encoder you will make use of your autoencoder, that has already being trained. You will just use the first half of the network, which contains the input and the bottleneck output. That way, you will obtain a 32 number output which represents the encoded version of the input image.
Then, you will apply your autoencoder to noisy images from MNIST, it should be able to clean the noisy artifacts.
The digits in this noisy dataset look like this: 
def show_encodings(encoded_imgs,number=1):
n = 5 # how many digits we will display
original = X_test_noise
original = original[np.where(y_test_noise == number)]
encoded_imgs = encoded_imgs[np.where(y_test_noise == number)]
plt.figure(figsize=(20, 4))
#plt.title('Original '+str(number)+' vs Encoded representation')
for i in range(min(n,len(original))):
# display original imgs
ax = plt.subplot(2, n, i + 1)
plt.imshow(original[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display encoded imgs
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(np.tile(encoded_imgs[i],(32,1)))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
def compare_plot(original,decoded_imgs):
n = 4 # How many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
# Display original
ax = plt.subplot(2, n, i + 1)
plt.imshow(original[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Display reconstruction
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.title('Noisy vs Decoded images')autoencoder.fit(X_train, X_train,
epochs=100,
batch_size=256,
shuffle=True,
validation_data=(X_test, X_test), verbose=0);encoder = Sequential()
encoder.add(autoencoder.layers[0])
# Encode the noisy images and show the encodings for your favorite number [0-9]
encodings = encoder.predict(X_test_noise)
show_encodings(encodings, number=1)4/4 [==============================] - 0s 23ms/step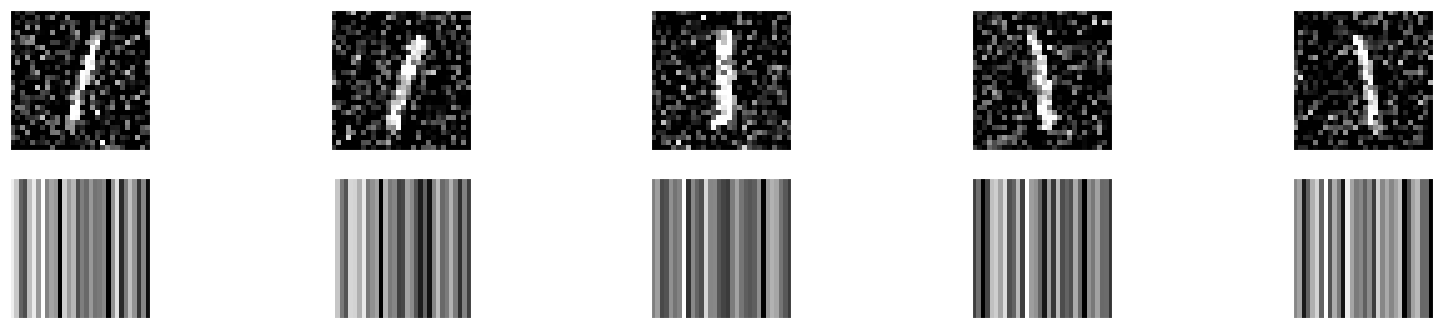
decoder_layer = autoencoder.layers[-1]
decoder = tf.keras.models.Model()
# Predict on the noisy images with your autoencoder
decoded_imgs = autoencoder.predict(X_test)
# Plot noisy vs decoded images
compare_plot(X_test, decoded_imgs)313/313 [==============================] - 0s 1ms/step
decoded_imgs = autoencoder.predict(X_test_noise)
# Plot noisy vs decoded images
compare_plot(X_test_noise, decoded_imgs)4/4 [==============================] - 0s 6ms/step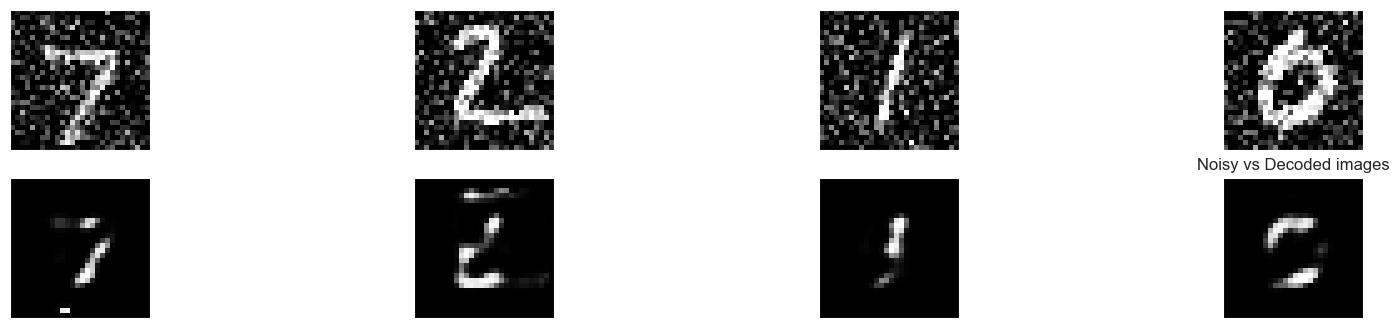
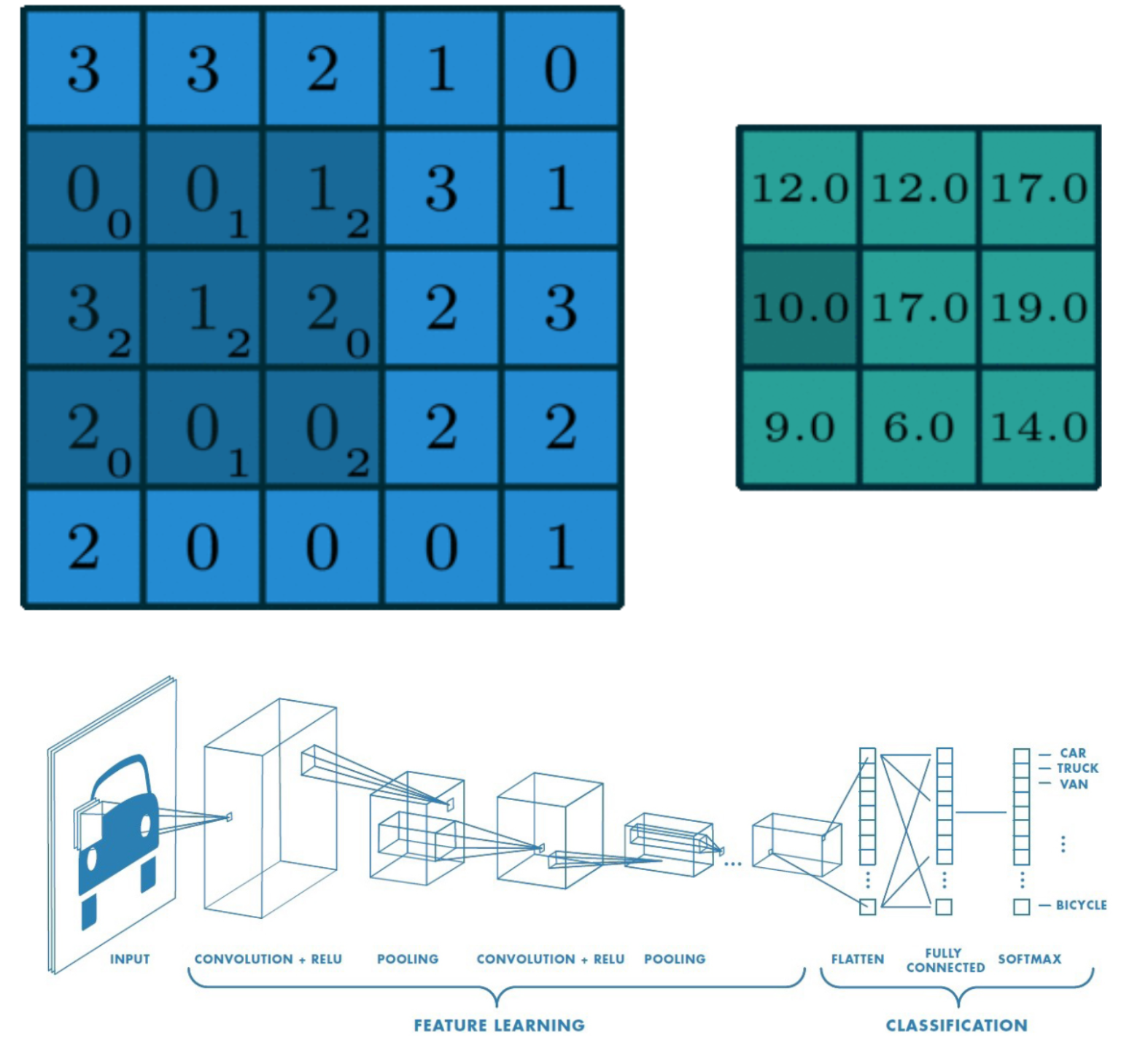




Building a CNN model in Keras isn’t much more difficult than building any of the models you’ve already built throughout the course! You just need to make use of convolutional layers.
You’re going to build a shallow convolutional model that classifies the MNIST dataset of digits. The same one you de-noised with your autoencoder!. The images are 28×28 pixels and just have one channel.
Go ahead and build this small convolutional model!
# Import the Conv2D and Flatten layers and instantiate model
from tensorflow.keras.layers import Conv2D,Flatten
model = Sequential()
# Add a convolutional layer of 32 filters of size 3x3
model.add(Conv2D(32, kernel_size = 3, input_shape = (28, 28, 1), activation = 'relu'))
# Add a convolutional layer of 16 filters of size 3x3
model.add(Conv2D(16, kernel_size=3, activation = 'relu'))
# Flatten the previous layer output
model.add(Flatten())
# Add as many outputs as classes with softmax activation
model.add(Dense(10, activation = 'softmax'))Inspecting the activations of a convolutional layer is a cool thing. You have to do it at least once in your lifetime!
To do so, you will build a new model with the Keras Model object, which takes in a list of inputs and a list of outputs. The output you will provide to this new model is the first convolutional layer outputs when given an MNIST digit as input image.
Let’s look at the convolutional masks that were learned in the first convolutional layer of this model!
model.summary()Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
conv2d_1 (Conv2D) (None, 24, 24, 16) 4624
flatten (Flatten) (None, 9216) 0
dense_4 (Dense) (None, 10) 92170
=================================================================
Total params: 97,114
Trainable params: 97,114
Non-trainable params: 0
_________________________________________________________________(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = np.reshape(X_train, [-1, 28, 28, 1])
X_test = np.reshape(X_test, [-1, 28, 28, 1])model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=30, batch_size=32);Epoch 1/30
1875/1875 [==============================] - 9s 4ms/step - loss: 0.2244 - accuracy: 0.9488
Epoch 2/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0712 - accuracy: 0.9783
Epoch 3/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0523 - accuracy: 0.9841
Epoch 4/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0402 - accuracy: 0.9877
Epoch 5/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0308 - accuracy: 0.9906
Epoch 6/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0259 - accuracy: 0.9920
Epoch 7/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0253 - accuracy: 0.9930
Epoch 8/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0188 - accuracy: 0.9946
Epoch 9/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0201 - accuracy: 0.9947
Epoch 10/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0144 - accuracy: 0.9959
Epoch 11/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0171 - accuracy: 0.9958
Epoch 12/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0165 - accuracy: 0.9960
Epoch 13/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0167 - accuracy: 0.9965
Epoch 14/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0185 - accuracy: 0.9967
Epoch 15/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0112 - accuracy: 0.9973
Epoch 16/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0199 - accuracy: 0.9965
Epoch 17/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0169 - accuracy: 0.9971
Epoch 18/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0161 - accuracy: 0.9972
Epoch 19/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0135 - accuracy: 0.9978
Epoch 20/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0165 - accuracy: 0.9979
Epoch 21/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0179 - accuracy: 0.9976
Epoch 22/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0153 - accuracy: 0.9976
Epoch 23/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0159 - accuracy: 0.9980
Epoch 24/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0181 - accuracy: 0.9977
Epoch 25/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0162 - accuracy: 0.9981
Epoch 26/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0154 - accuracy: 0.9981
Epoch 27/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0187 - accuracy: 0.9982
Epoch 28/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0141 - accuracy: 0.9982
Epoch 29/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0101 - accuracy: 0.9987
Epoch 30/30
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0119 - accuracy: 0.9987# Obtain a reference to the outputs of the first layer
first_layer_output = model.layers[0].output
# Build a model using the model's input and the first layer output
first_layer_model = tf.keras.models.Model(inputs = model.layers[0].input, outputs = first_layer_output)
# Use this model to predict on X_test
activations = first_layer_model.predict(X_test)
fig, axs = plt.subplots(1, 3, figsize=(16, 8))
# Plot the activations of first digit of X_test for the 15th filter
axs[0].matshow(activations[0,:,:,14], cmap = 'viridis')
# Do the same but for the 18th filter now
axs[1].matshow(activations[0,:,:,17], cmap = 'viridis')
plt.show()313/313 [==============================] - 0s 996us/step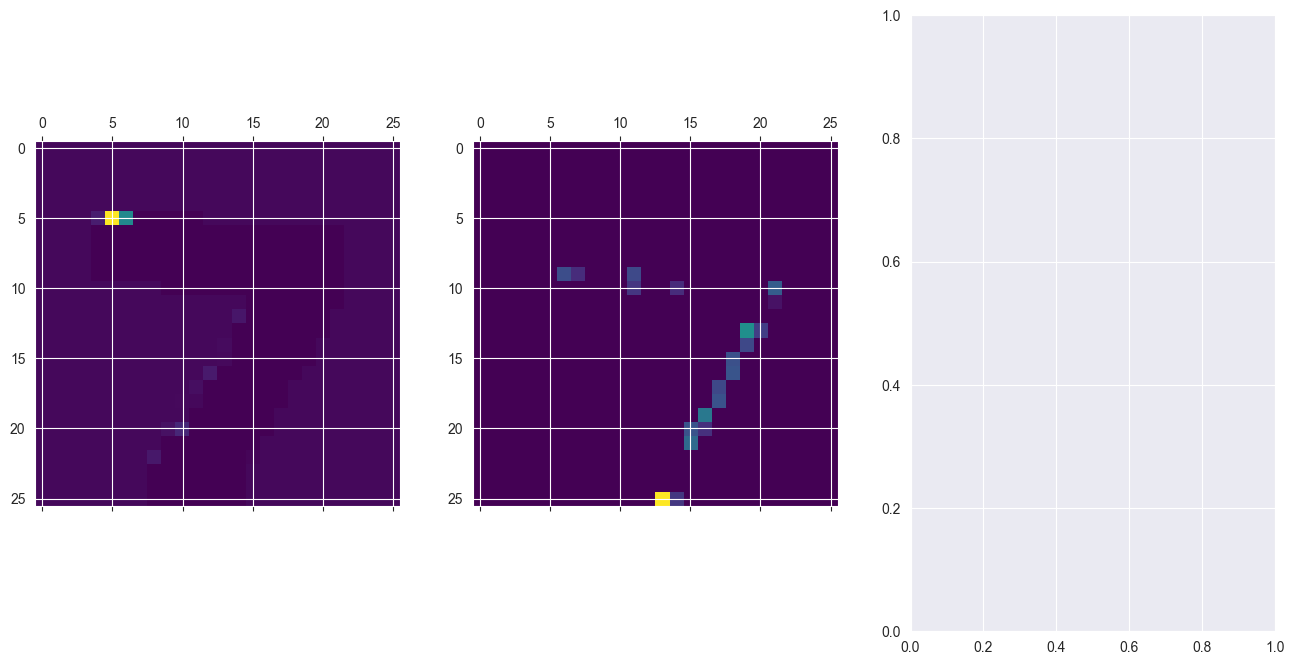
print("\nEach neuron filter of the first layer learned a different convolution. The 15th filter (a.k.a convolutional mask) learned to detect horizontal traces in your digits. On the other hand, filter 18th seems to be checking for vertical traces")The original ResNet50 model was trained with images of size 224 x 224 pixels and a number of preprocessing operations; like the subtraction of the mean pixel value in the training set for all training images. You need to pre-process the images you want to predict on in the same way.
When predicting on a single image you need it to fit the model’s input shape, which in this case looks like this: (batch-size, width, height, channels),np.expand_dims with parameter axis = 0 adds the batch-size dimension, representing that a single image will be passed to predict. This batch-size dimension value is 1, since we are only predicting on one image.
You will go over these preprocessing steps as you prepare this dog’s (named Ivy) image into one that can be classified by ResNet50.

from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.resnet50 import preprocess_input
# Load the image with the right target size for your model
img = image.load_img('dataset/dog.png', target_size=(224, 224))
# Turn it into an array
img_array = image.img_to_array(img)
# Expand the dimensions of the image, this is so that it fits the expected model input format
img_expanded = np.expand_dims(img_array, axis=0)
# Pre-process the img in the same way original images were
img_ready = preprocess_input(img_expanded)Okay, so Ivy’s picture is ready to be used by ResNet50. It is stored in img_ready and now looks like this: dogp ResNet50 is a model trained on the Imagenet dataset that is able to distinguish between 1000 different labeled objects. ResNet50 is a deep model with 50 layers, you can check it in 3D here. It’s time to use this trained model to find out Ivy’s breed!
from tensorflow.keras.applications.resnet50 import ResNet50, decode_predictions
# Instantiate a ResNet50 model with 'imagenet' weights
model = ResNet50(weights='imagenet')
# Predict with ResNet50 on your already processed img
preds = model.predict(img_ready)
# Decode the first 3 predictions
print('Predicted:', decode_predictions(preds, top=3)[0])Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/resnet/resnet50_weights_tf_dim_ordering_tf_kernels.h5
102967424/102967424 [==============================] - 16s 0us/step
1/1 [==============================] - 2s 2s/step
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json
35363/35363 [==============================] - 0s 9us/step
Predicted: [('n02088364', 'beagle', 0.90737635), ('n02089867', 'Walker_hound', 0.06626681), ('n02089973', 'English_foxhound', 0.018850895)]img = image.load_img('dataset/grace.jpg', target_size=(224, 224))
img_array = image.img_to_array(img)
img_expanded = np.expand_dims(img_array, axis=0)
img_ready = preprocess_input(img_expanded)
plt.imshow(img);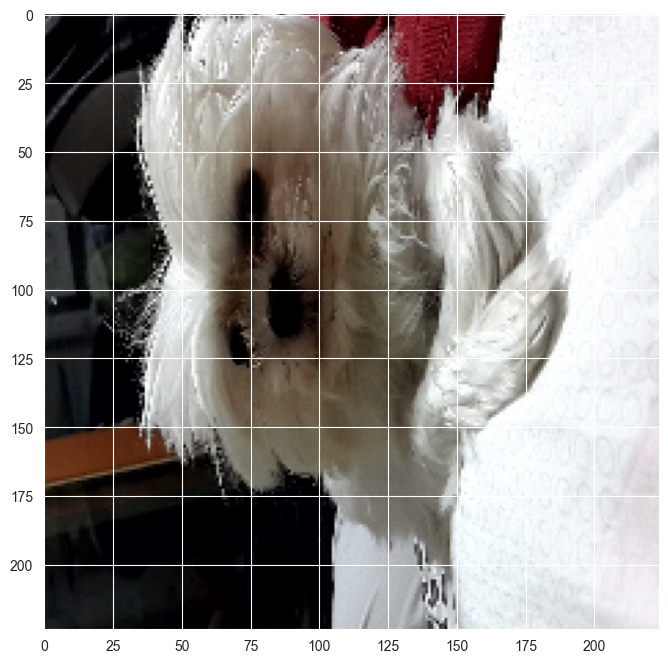
preds = model.predict(img_ready)
# Decode the first 3 predictions
print('Predicted:', decode_predictions(preds, top=3)[0])1/1 [==============================] - 0s 27ms/step
Predicted: [('n02085936', 'Maltese_dog', 0.17497465), ('n02098286', 'West_Highland_white_terrier', 0.12481641), ('n02086240', 'Shih-Tzu', 0.09362529)]
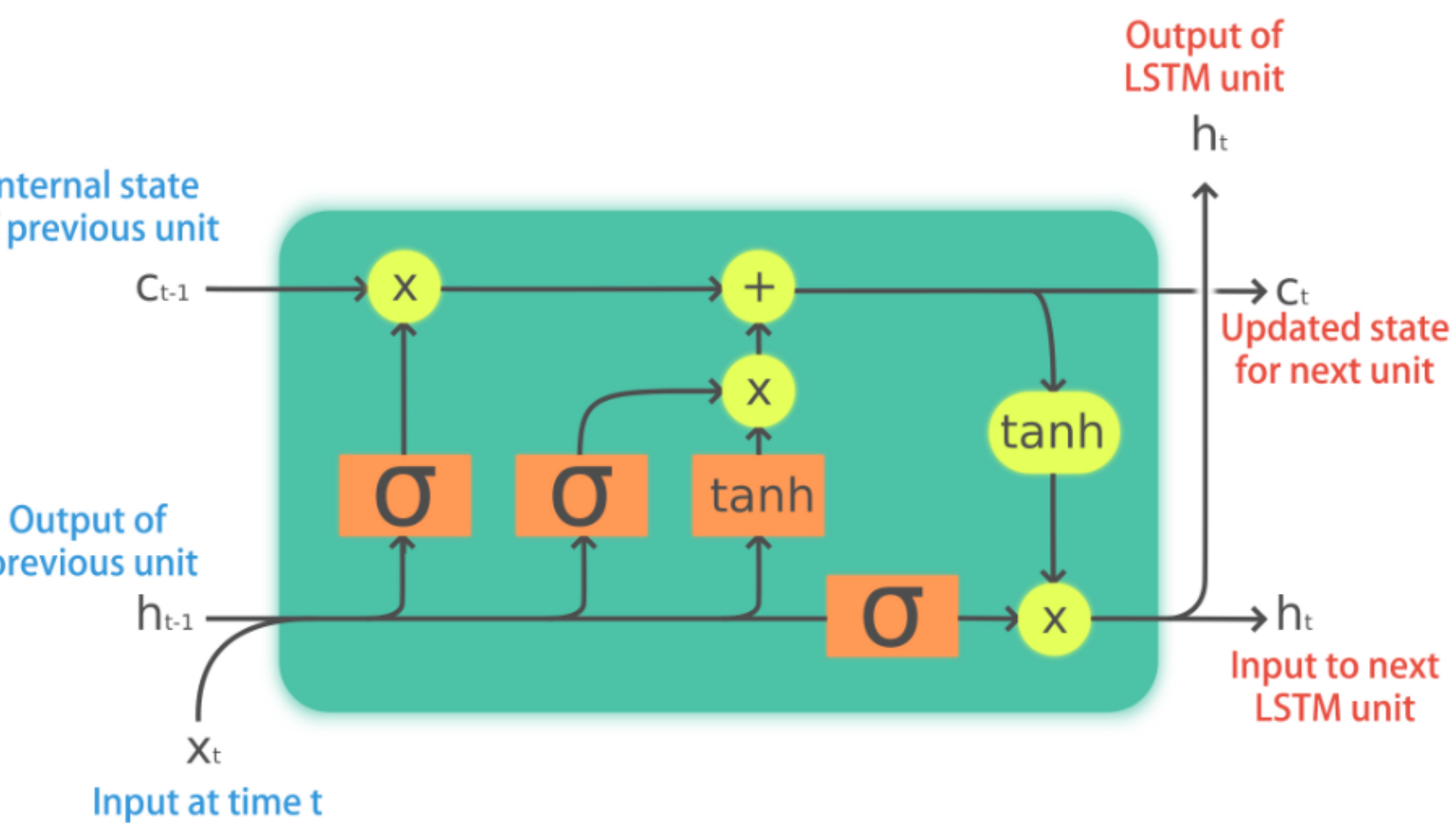
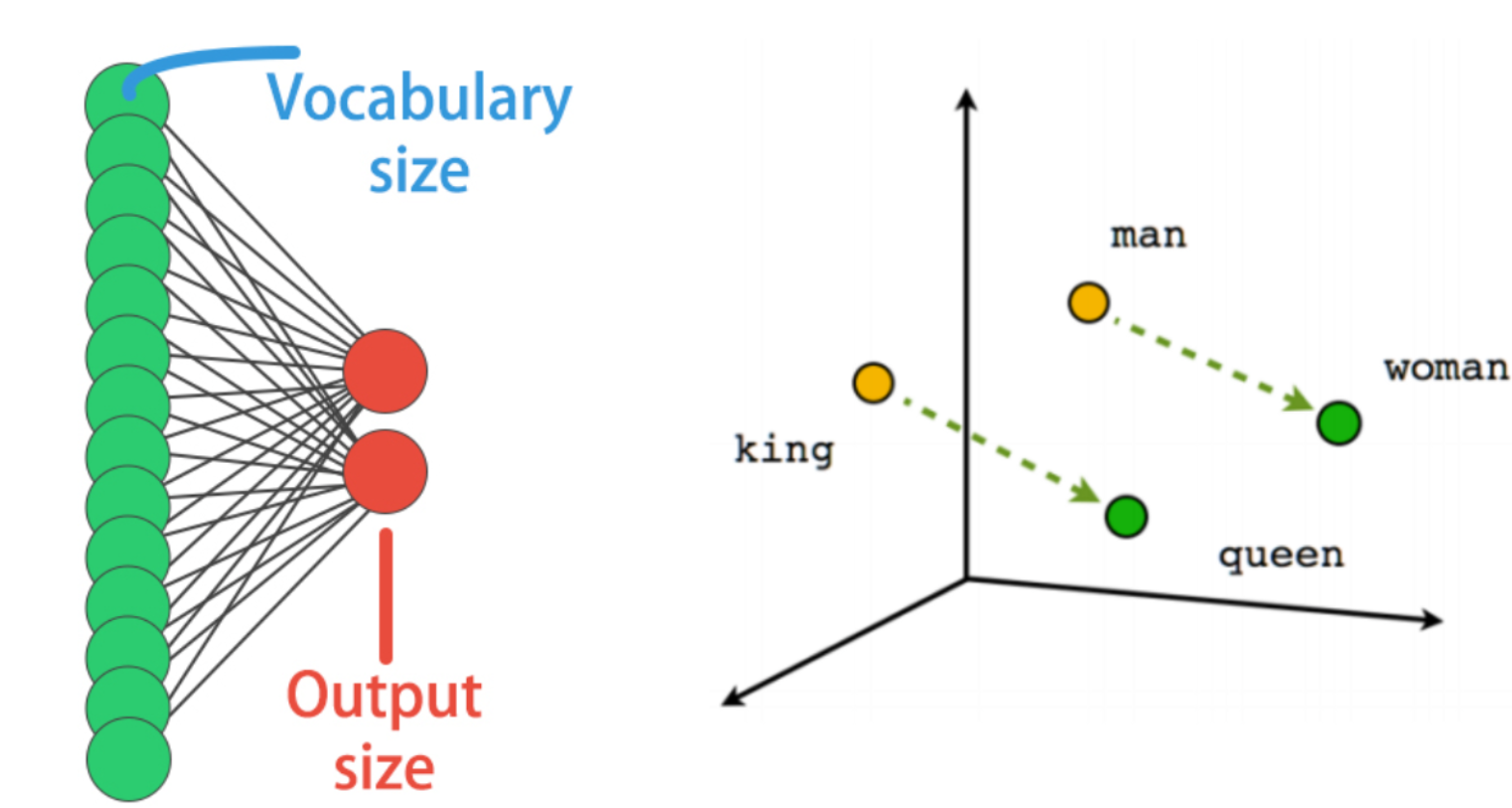
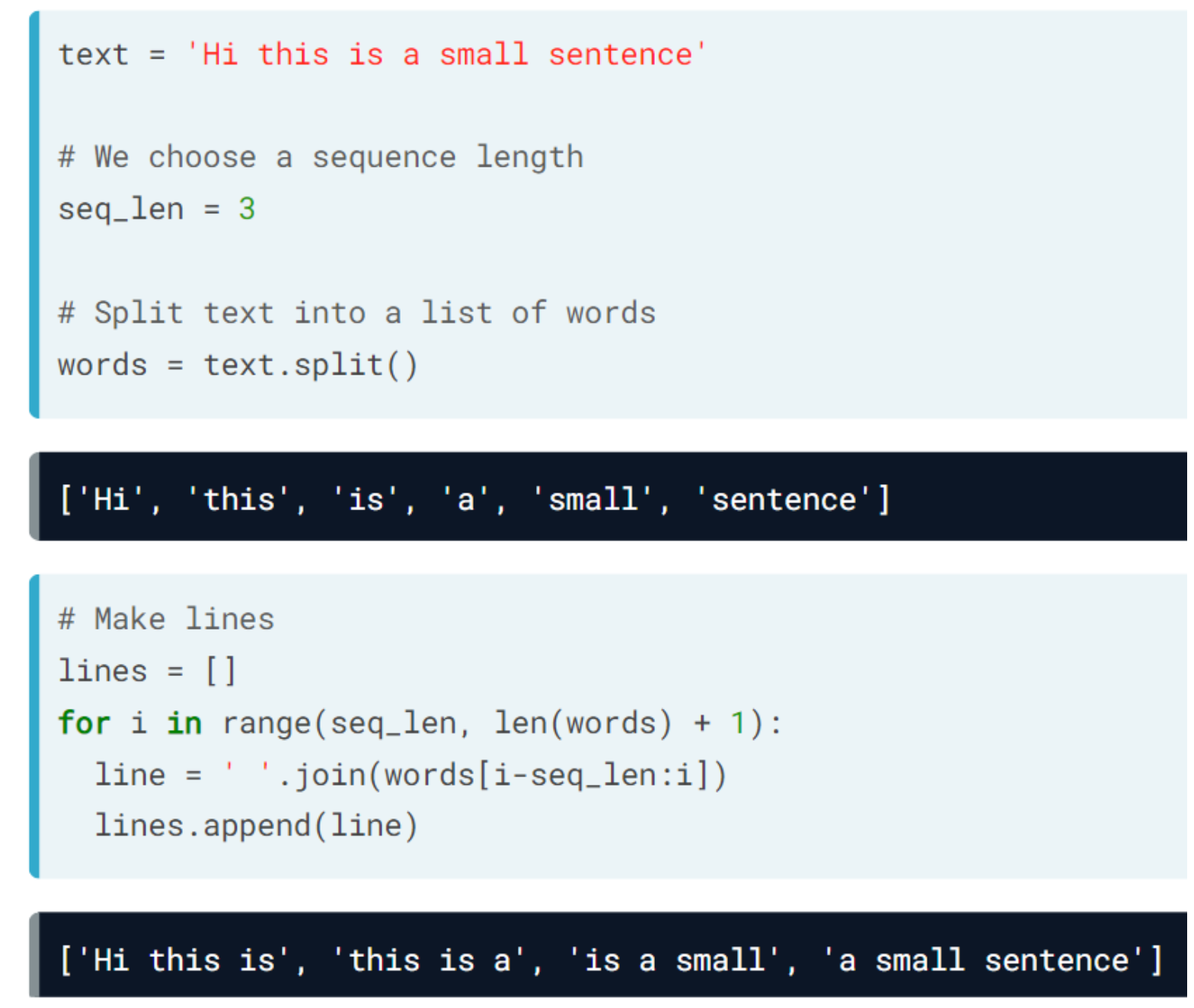
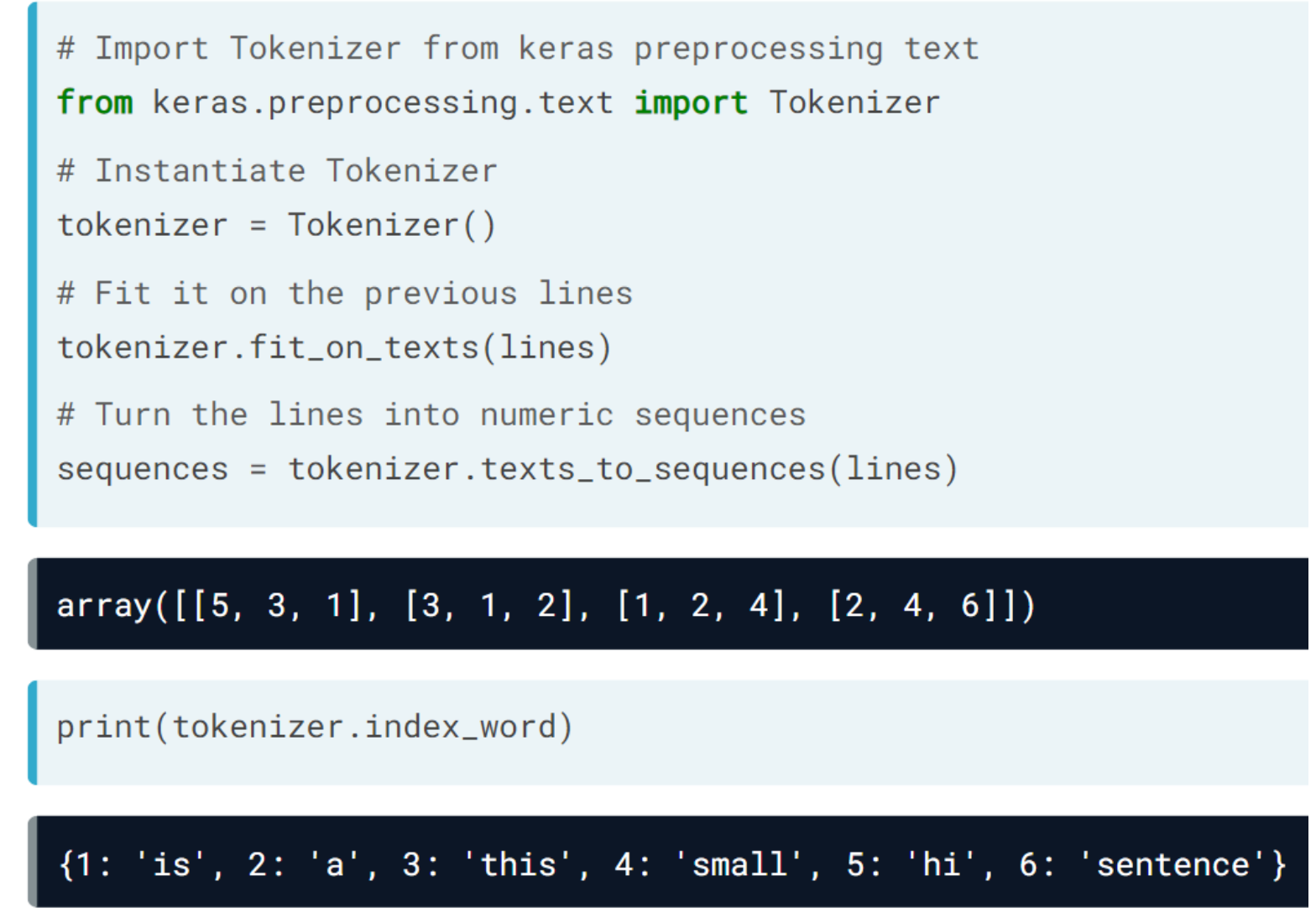
During the following exercises you will build a toy LSTM model that is able to predict the next word using a small text dataset. This dataset consist of cleaned quotes from the The Lord of the Ring movies.
You will turn this text into sequences of length 4 and make use of the Keras Tokenizer to prepare the features and labels for your model!
The Keras Tokenizer is already imported for you to use. It assigns a unique number to each unique word, and stores the mappings in a dictionary. This is important since the model deals with numbers but we later will want to decode the output numbers back into words
text = '''
it is not the strength of the body but the strength of the spirit it is useless to meet revenge
with revenge it will heal nothing even the smallest person can change the course of history all we have
to decide is what to do with the time that is given us the burned hand teaches best after that advice about
fire goes to the heart END
'''from tensorflow.keras.preprocessing.text import Tokenizer
# Split text into an array of words
words = text.split()
# Make sentences of 4 words each, moving one word at a time
sentences = []
for i in range(4, len(words) + 1):
sentences.append(' '.join(words[i - 4: i]))
# Instantiate a Tokenizer, then fit it on the sentences
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)
# Turn sentences into a sequence of numbers
sequences = tokenizer.texts_to_sequences(sentences)
print("Sentences: \n {} \n Sequences: \n {}".format(sentences[:5], sequences[:5]))Sentences:
['it is not the', 'is not the strength', 'not the strength of', 'the strength of the', 'strength of the body']
Sequences:
[[5, 3, 43, 1], [3, 43, 1, 6], [43, 1, 6, 4], [1, 6, 4, 1], [6, 4, 1, 10]]print("\nYour sentences are now sequences of numbers, check that identical words are assigned the same number.")
Your sentences are now sequences of numbers, check that identical words are assigned the same number.You’ve already prepared your sequences of text. It’s time to build your LSTM model!
Remember your sequences had 4 words each, your model will be trained on the first three words of each sequence, predicting the 4th one. You are going to use an Embedding layer that will essentially learn to turn words into vectors. These vectors will then be passed to a simple LSTM layer. Our output is a Dense layer with as many neurons as words in the vocabulary and softmax activation. This is because we want to obtain the highest probable next word out of all possible words.
vocab_size = len(tokenizer.word_counts) + 1
vocab_size46from tensorflow.keras.layers import Embedding, LSTM
model = Sequential()
# Add an Embedding layer with the right parameters
model.add(Embedding(input_dim=vocab_size, input_length=3, output_dim=8))
# Add a 32 unit LSTM layer
model.add(LSTM(32))
# Add a hidden Dense layer of 32 units
model.add(Dense(32, activation='relu'))
model.add(Dense(vocab_size, activation='softmax'))
model.summary()Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 3, 8) 368
lstm (LSTM) (None, 32) 5248
dense_5 (Dense) (None, 32) 1056
dense_6 (Dense) (None, 46) 1518
=================================================================
Total params: 8,190
Trainable params: 8,190
Non-trainable params: 0
_________________________________________________________________print("\nYou'll see that this model is powerful enough to learn text relationships, we aren't using a lot of text in this tiny example and our sequences are quite short. This model is to be trained as usual, you would just need to compile it with an optimizer like adam and use crossentropy loss. This is because we have modeled this next word prediction task as a classification problem with all the unique words in our vocabulary as candidate classes.")
You'll see that this model is powerful enough to learn text relationships, we aren't using a lot of text in this tiny example and our sequences are quite short. This model is to be trained as usual, you would just need to compile it with an optimizer like adam and use crossentropy loss. This is because we have modeled this next word prediction task as a classification problem with all the unique words in our vocabulary as candidate classes.Your LSTM model has already been trained for you so that you don’t have to wait. It’s time to define a function that decodes its predictions.
Since you are predicting on a model that uses the softmax function,argmax() is used to obtain the position of the output layer with the highest probability, that is the index representing the most probable next word.
The tokenizer you previously created and fitted, is loaded for you. You will be making use of its internal index_word dictionary to turn the model’s next word prediction (which is an integer) into the actual written word it represents.
You’re very close to experimenting with your model!
from tensorflow.keras.utils import to_categorical
np_sequences = np.array(sequences)
print(np_sequences.shape)
X = np_sequences[:, :3]
y = np_sequences[:, 3]
y = to_categorical(y, num_classes=vocab_size)(64, 4)model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(X, y, epochs=500, verbose=0);def predict_text(test_text, model=model):
if len(test_text.split()) != 3:
print('Text input should be 3 words')
return False
# Turn the test_text into a sequence of numbers
test_seq = tokenizer.texts_to_sequences([test_text])
test_seq = np.array(test_seq)
# Use the model passed as a parameter to predict the next word
pred = model.predict(test_seq).argmax(axis=1)[0]
# Return the word that maps to the prediction
return tokenizer.index_word[pred]predict_text('meet revenge with')1/1 [==============================] - 1s 626ms/step'revenge'predict_text('the course of')1/1 [==============================] - 0s 10ms/step'history'predict_text('strength of the')1/1 [==============================] - 0s 11ms/step'body'def plot_graphs(history, string):
plt.plot(history.history[string])
plt.xlabel('Epochs')
plt.ylabel(string)
plot_graphs(history, 'accuracy')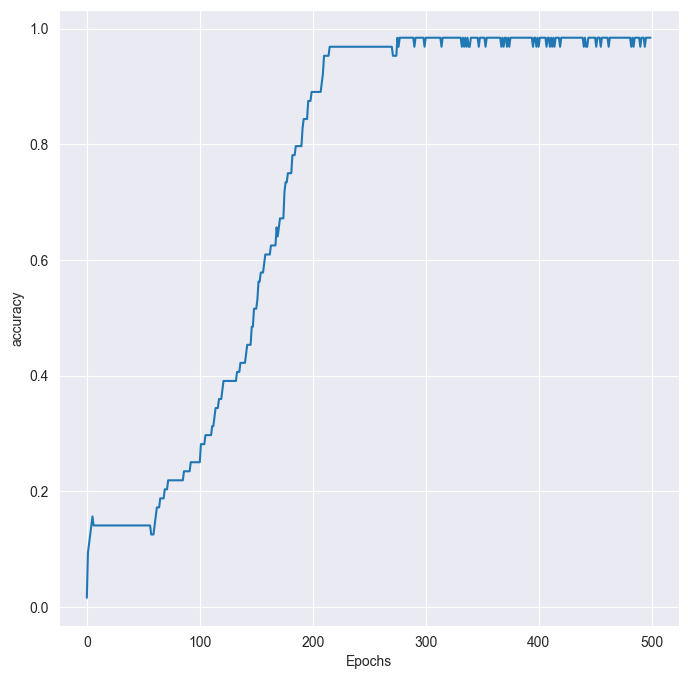
text = 'meet revenge with'
story = [text]
for i in range(100):
result = predict_text(text)
if result == "end":
break;
story.append(result)
text += ' ' + result
text = ' '.join(text.split()[1:])
story = " ".join(str(x) for x in story)
print('Final story : {}'.format(story))1/1 [==============================] - 0s 12ms/step
1/1 [==============================] - 0s 12ms/step
1/1 [==============================] - 0s 12ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 11ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 10ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 8ms/step
Final story : meet revenge with revenge it will heal nothing even the smallest person can change the course of history all we have to decide is what to do with the time that is given us the burned hand teaches best after that advice about fire goes to the heart